Evaluating KOMPUTE - Open Field Data
Coby Warkentin and Donghyung Lee
2023-07-03
- Load packages
- Preparing control phenotype
data
- Importing Open Field Control Phenotype Dataset
- Visualizing measured phenotypes via a heatmap
- Exclude phenotypes with fewer than 15,000 observations
- Remove samples with fewer than 10 measured phenotypes
- Heapmap of filtered phenotypes
- Reforatting the dataset (long to wide)
- Visualizing phenotype distributions
- Rank Z transformation
- Conducting Principal Variance Component Analysis (PVCA)
- Batch effect removal using ComBat
- PVCA on ComBat residuals
- Computing phenotypic correlations
- Preparation of IMPC
summary statistics data
- Loading Open Field summary stat (IMPCv16)
- Visualizing gene-phenotype pair duplicates
- Consolidating muliple z-scores of a gene-phenotype pair using Stouffer’s Method
- Generating Z-score matrix (reformatting)
- Visualization of Phenotype-Gene Coverage
- Distribution of Z-Scores Across Phenotypes
- Estimation of Genetic Correlation Matrix Using Z-Scores
- Comparison of Phenotypic Correlation and Genetic Correlation Among Phenotypes
- Correlation Analysis Between Genetic Correlation Matrices Using Mantel’s Test
- Evaluating the KOMPUTE Imputation Algorithm
Last updated: 2023-07-03
Checks: 7 0
Knit directory: komputeExamples/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230110) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 0bd39c6. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: code/.DS_Store
Untracked files:
Untracked: analysis/kompute_test_app_v16.Rmd
Unstaged changes:
Modified: data/BC.imp.res.v16.RData
Modified: data/CC.imp.res.v16.RData
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/kompute_test_OF_v16.Rmd)
and HTML (docs/kompute_test_OF_v16.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 0bd39c6 | statsleelab | 2023-07-03 | typo fix |
| html | b343ff3 | statsleelab | 2023-07-03 | svd mc added |
| Rmd | dbdfbca | statsleelab | 2023-07-03 | svd mc added |
| html | 0ad952c | statsleelab | 2023-06-23 | kompute function input format changed |
| Rmd | fbd0f5c | statsleelab | 2023-06-23 | kompute input format changed |
| html | dcb3b0d | statsleelab | 2023-06-21 | pheno.cor added |
| Rmd | e7a365f | statsleelab | 2023-06-21 | pheno.cor added |
| html | 9b680ec | statsleelab | 2023-06-20 | doc updated |
| Rmd | d343f6a | statsleelab | 2023-06-20 | doc updated |
| html | d56cc7a | statsleelab | 2023-06-19 | Build site. |
| Rmd | 998966f | statsleelab | 2023-01-10 | v16 updated |
| Rmd | 7685a09 | statsleelab | 2023-01-10 | first commit |
| html | 7685a09 | statsleelab | 2023-01-10 | first commit |
Load packages
rm(list=ls())
knitr::opts_chunk$set(message = FALSE, warning = FALSE)
library(data.table)
library(dplyr)
library(reshape2)
library(ggplot2)
library(tidyr) #spread
library(RColorBrewer)
library(circlize)
library(ComplexHeatmap)Preparing control phenotype data
Importing Open Field Control Phenotype Dataset
OF.data <- readRDS("data/OF.data.rds")
#dim(OF.data)Visualizing measured phenotypes via a heatmap
The heatmap below presents a visualization of the phenotypic measurements taken for each control mouse. The columns represent individual mice, while the rows correspond to the distinct phenotypes measured.
mtest <- table(OF.data$proc_param_name_stable_id, OF.data$biological_sample_id)
mtest <-as.data.frame.matrix(mtest)
#dim(mtest)
if(FALSE){
nmax <-max(mtest)
library(circlize)
col_fun = colorRamp2(c(0, nmax), c("white", "red"))
col_fun(seq(0, nmax))
ht = Heatmap(as.matrix(mtest), cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, col = col_fun,
row_names_gp = gpar(fontsize = 8), name="Count")
draw(ht)
}Exclude phenotypes with fewer than 15,000 observations
To maintain data quality and robustness, we will discard any phenotypes that have fewer than 15,000 recorded observations.
mtest <- table(OF.data$proc_param_name, OF.data$biological_sample_id)
#dim(mtest)
#head(mtest[,1:10])
mtest0 <- mtest>0
#head(mtest0[,1:10])
#rowSums(mtest0)
rmv.pheno.list <- rownames(mtest)[rowSums(mtest0)<15000]
#rmv.pheno.list
#dim(OF.data)
OF.data <- OF.data %>% filter(!(proc_param_name %in% rmv.pheno.list))
#dim(OF.data)
# number of phenotypes left
#length(unique(OF.data$proc_param_name))Remove samples with fewer than 10 measured phenotypes
mtest <- table(OF.data$proc_param_name, OF.data$biological_sample_id)
#dim(mtest)
#head(mtest[,1:10])
mtest0 <- mtest>0
#head(mtest0[,1:10])
#summary(colSums(mtest0))
rmv.sample.list <- colnames(mtest)[colSums(mtest0)<10]
#length(rmv.sample.list)
#dim(OF.data)
OF.data <- OF.data %>% filter(!(biological_sample_id %in% rmv.sample.list))
#dim(OF.data)
# number of observations to use
#length(unique(OF.data$biological_sample_id))Heapmap of filtered phenotypes
if(FALSE){
mtest <- table(OF.data$proc_param_name, OF.data$biological_sample_id)
dim(mtest)
mtest <-as.data.frame.matrix(mtest)
nmax <-max(mtest)
library(circlize)
col_fun = colorRamp2(c(0, nmax), c("white", "red"))
col_fun(seq(0, nmax))
pdf("~/Google Drive Miami/Miami_IMPC/output/measured_phenotypes_controls_after_filtering_OF.pdf", width = 10, height = 3)
ht = Heatmap(as.matrix(mtest), cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, col = col_fun,
row_names_gp = gpar(fontsize = 7), name="Count")
draw(ht)
dev.off()
}Reforatting the dataset (long to wide)
We restructure our data from a long format to a wide one for further processing and analysis.
OF.mat <- OF.data %>%
dplyr::select(biological_sample_id, proc_param_name, data_point, sex, phenotyping_center, strain_name) %>%
##consider weight or age in weeks
arrange(biological_sample_id) %>%
distinct(biological_sample_id, proc_param_name, .keep_all=TRUE) %>% ## remove duplicates, maybe mean() is better.
spread(proc_param_name, data_point) %>%
tibble::column_to_rownames(var="biological_sample_id")
head(OF.mat) sex phenotyping_center strain_name
21653 female WTSI C57BL/6Brd-Tyr<c-Brd> * C57BL/6N
21713 female WTSI C57BL/6Brd-Tyr<c-Brd> * C57BL/6N
21742 male WTSI C57BL/6Brd-Tyr<c-Brd> * C57BL/6N
21745 male WTSI C57BL/6Brd-Tyr<c-Brd> * C57BL/6N
21747 male WTSI C57BL/6Brd-Tyr<c-Brd> * C57BL/6N
21751 male WTSI C57BL/6Brd-Tyr<c-Brd> * C57BL/6N
OF_Center average speed OF_Center distance travelled
21653 51.5 4259
21713 40.1 3266
21742 51.0 710
21745 38.0 2580
21747 31.4 3022
21751 14.9 1723
OF_Center permanence time OF_Center resting time
21653 102 20
21713 87 6
21742 17 3
21745 100 33
21747 134 39
21751 240 130
OF_Distance travelled - total OF_Latency to center entry
21653 NA 5.0
21713 NA 6.1
21742 NA 24.0
21745 NA 8.3
21747 NA 6.6
21751 NA 18.7
OF_Number of center entries OF_Percentage center time
21653 193 NA
21713 221 NA
21742 73 NA
21745 165 NA
21747 210 NA
21751 75 NA
OF_Periphery average speed OF_Periphery distance travelled
21653 35.3 12923
21713 31.9 11625
21742 19.1 5769
21745 25.1 7910
21747 26.0 8208
21751 11.5 2150
OF_Periphery permanence time OF_Periphery resting time
21653 498 135
21713 513 152
21742 583 292
21745 500 191
21747 466 154
21751 360 184
OF_Whole arena average speed OF_Whole arena permanence
21653 38.3 600
21713 33.4 600
21742 20.5 600
21745 27.4 600
21747 27.2 600
21751 12.8 600
OF_Whole arena resting time
21653 155
21713 158
21742 295
21745 224
21747 193
21751 314#dim(OF.mat)
#summary(colSums(is.na(OF.mat[,-1:-3])))Visualizing phenotype distributions
ggplot(melt(OF.mat), aes(x=value)) +
geom_histogram() +
facet_wrap(~variable, scales="free", ncol=5)+
theme(strip.text.x = element_text(size = 6))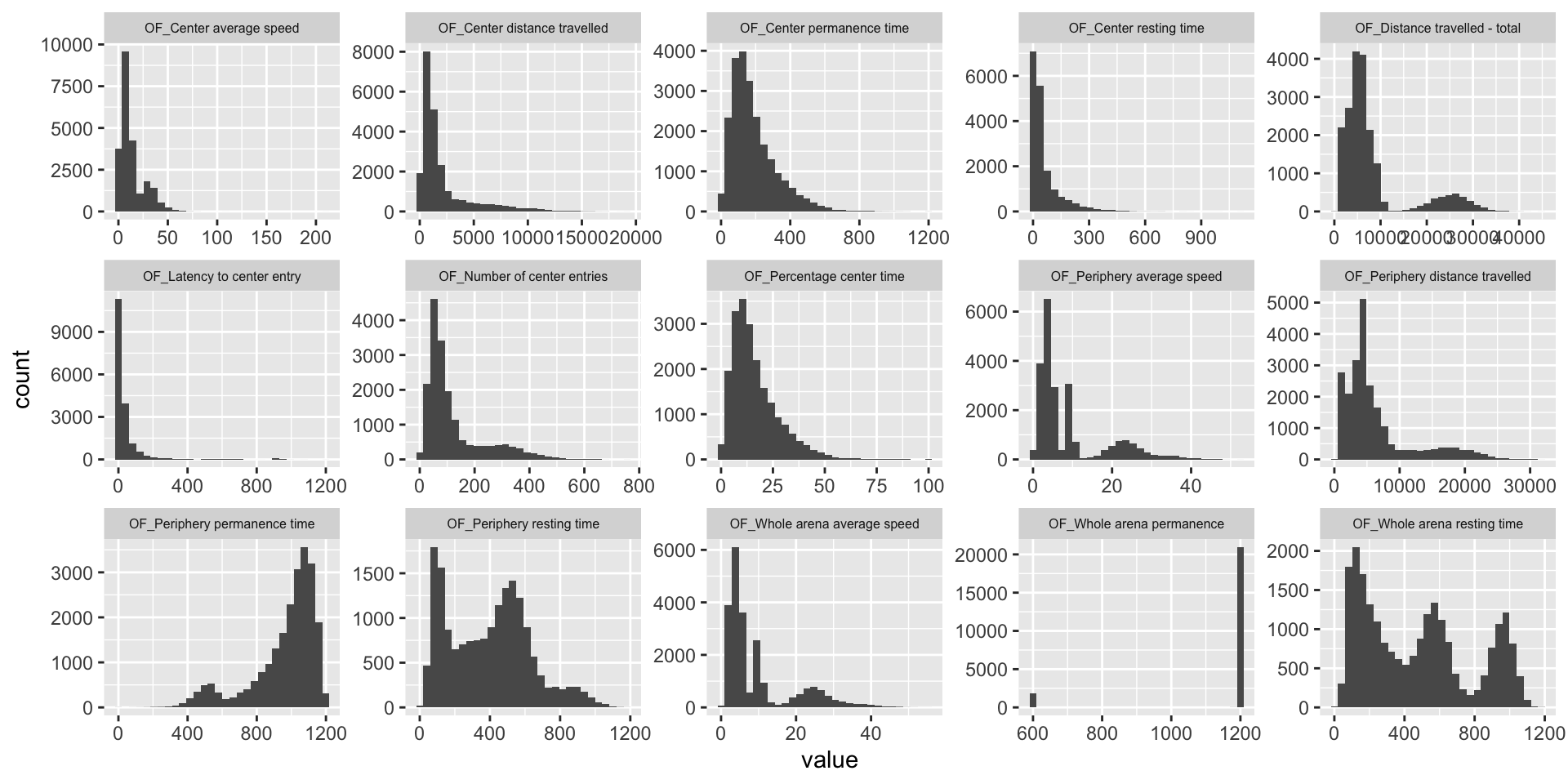
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
Rank Z transformation
In this step, we conduct a rank Z transformation on the phenotype data to ensure that the data is normally distributed
library(RNOmni)
OF.mat.rank <- OF.mat
#dim(OF.mat.rank)
OF.mat.rank <- OF.mat.rank[complete.cases(OF.mat.rank),]
#dim(OF.mat.rank)
#dim(OF.mat)
OF.mat <- OF.mat[complete.cases(OF.mat),]
#dim(OF.mat)
OF.mat.rank <- cbind(OF.mat.rank[,1:3], apply(OF.mat.rank[,-1:-3], 2, RankNorm))
ggplot(melt(OF.mat.rank), aes(x=value)) +
geom_histogram() +
facet_wrap(~variable, scales="free", ncol=5)+
theme(strip.text.x = element_text(size = 6))![]()
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
Conducting Principal Variance Component Analysis (PVCA)
In this step, we apply Principal Variance Component Analysis (PVCA) on the phenotype matrix data. PVCA is an approach that combines Principal Component Analysis (PCA) and Variance Component Analysis to quantify the proportion of total variance in the data attributed to each important covariate, in this case ‘sex’ and ‘phenotyping_center’.
First, we prepare our metadata which includes our chosen covariates. Any character variables in the metadata are then converted to factors. To avoid potential confounding, we check for associations between our covariates and drop ‘strain_name’ due to its strong association with ‘phenotyping_center’.
Next, we run PVCA on randomly chosen subsets of our phenotype data (for computational efficiency). Finally, we compute the average effect size across all random samples and visualize the results in a PVCA plot.
source("code/PVCA.R")
meta <- OF.mat.rank[,1:3] ## examining covariates sex, phenotyping_center, and strain_name
#head(meta)
#dim(meta)
#summary(meta) # variables are currently characters
meta[sapply(meta, is.character)] <- lapply(meta[sapply(meta, is.character)], as.factor)
#summary(meta) # now all variables are converted to factors
chisq.test(meta[,1],meta[,2])
Pearson's Chi-squared test
data: meta[, 1] and meta[, 2]
X-squared = 3.7637, df = 7, p-value = 0.8066chisq.test(meta[,2],meta[,3])
Pearson's Chi-squared test
data: meta[, 2] and meta[, 3]
X-squared = 29526, df = 21, p-value < 2.2e-16meta<-meta[,-3] # phenotyping_center and strain_name strongly associated which could cause confounding in the PVCA analysis, so we drop 'strain_name'.
G <- t(OF.mat.rank[,-1:-3]) # preparing the phenotype matrix data
set.seed(09302021)
# Perform PVCA for 10 random samples of size 1000 (more computationally efficient)
pvca.res <- matrix(nrow=10, ncol=3)
for (i in 1:10){
sample <- sample(1:ncol(G), 1000, replace=FALSE)
pvca.res[i,] <- PVCA(G[,sample], meta[sample,], threshold=0.6, inter=FALSE)
}
# Compute average effect size across the 10 random samples
pvca.means <- colMeans(pvca.res)
names(pvca.means) <- c(colnames(meta), "resid")
# Create PVCA plot
pvca.plot <- PlotPVCA(pvca.means, "PVCA of Phenotype Matrix Data")
pvca.plot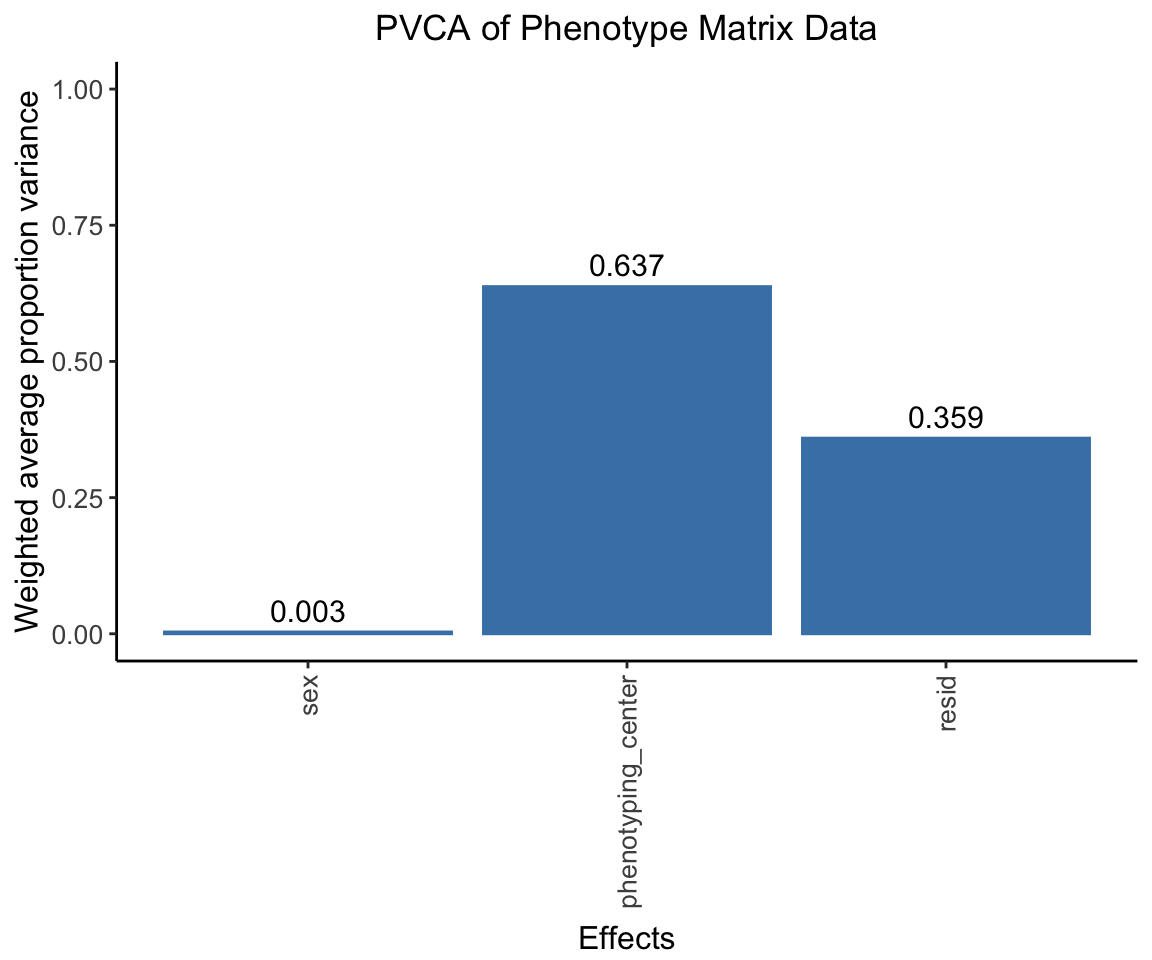
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
png(file="docs/figure/figures.Rmd/pvca_OF_1_v16.png", width=600, height=350)
pvca.plot
dev.off()quartz_off_screen
2 Batch effect removal using ComBat
We remove batch effects (the center effect) in the phenotype data set by using the ComBat method.
library(sva)
combat_komp = ComBat(dat=G, batch=meta$phenotyping_center, par.prior=TRUE, prior.plots=TRUE, mod=NULL)Found 1 genes with uniform expression within a single batch (all zeros); these will not be adjusted for batch.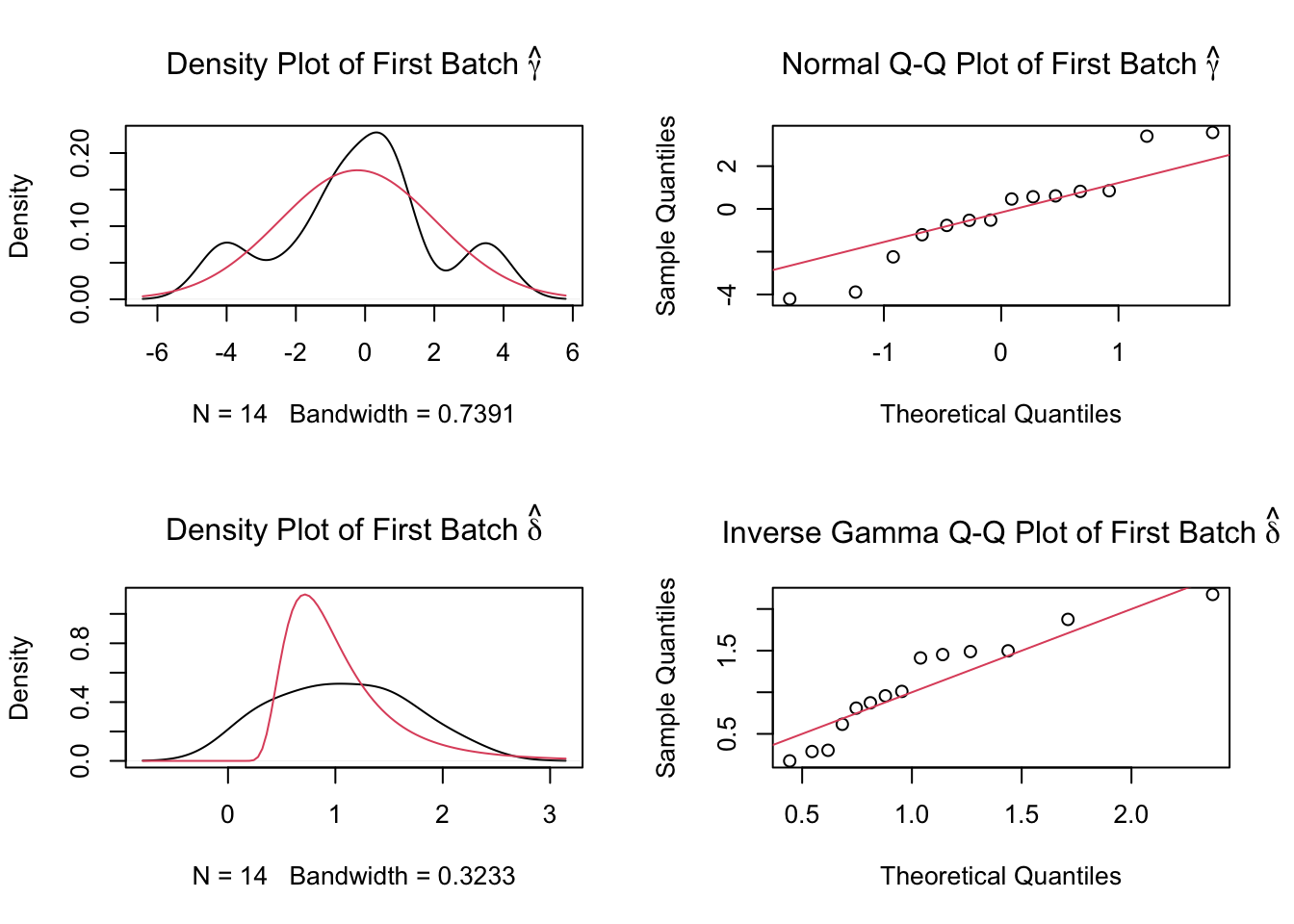
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
#combat_komp[1:5,1:5]
#G[1:5,1:5] # for comparison, combat_komp is same form and same dimensions as GPVCA on ComBat residuals
After using ComBat to account for batch effects, we perform a PVCA on the residuals. We expect to observe a significantly reduced effect from the phenotyping centers.
set.seed(09302021)
# Perform PVCA for 10 random samples (more computationally efficient)
pvca.res.nobatch <- matrix(nrow=10, ncol=3)
for (i in 1:10){
sample <- sample(1:ncol(combat_komp), 1000, replace=FALSE)
pvca.res.nobatch[i,] <- PVCA(combat_komp[,sample], meta[sample,], threshold=0.6, inter=FALSE)
}
# Compute average effect size across samples
pvca.means.nobatch <- colMeans(pvca.res.nobatch)
names(pvca.means.nobatch) <- c(colnames(meta), "resid")
# Generate PVCA plot
pvca.plot.nobatch <- PlotPVCA(pvca.means.nobatch, "PVCA of Phenotype Matrix Data with Reduced Batch Effect")
pvca.plot.nobatch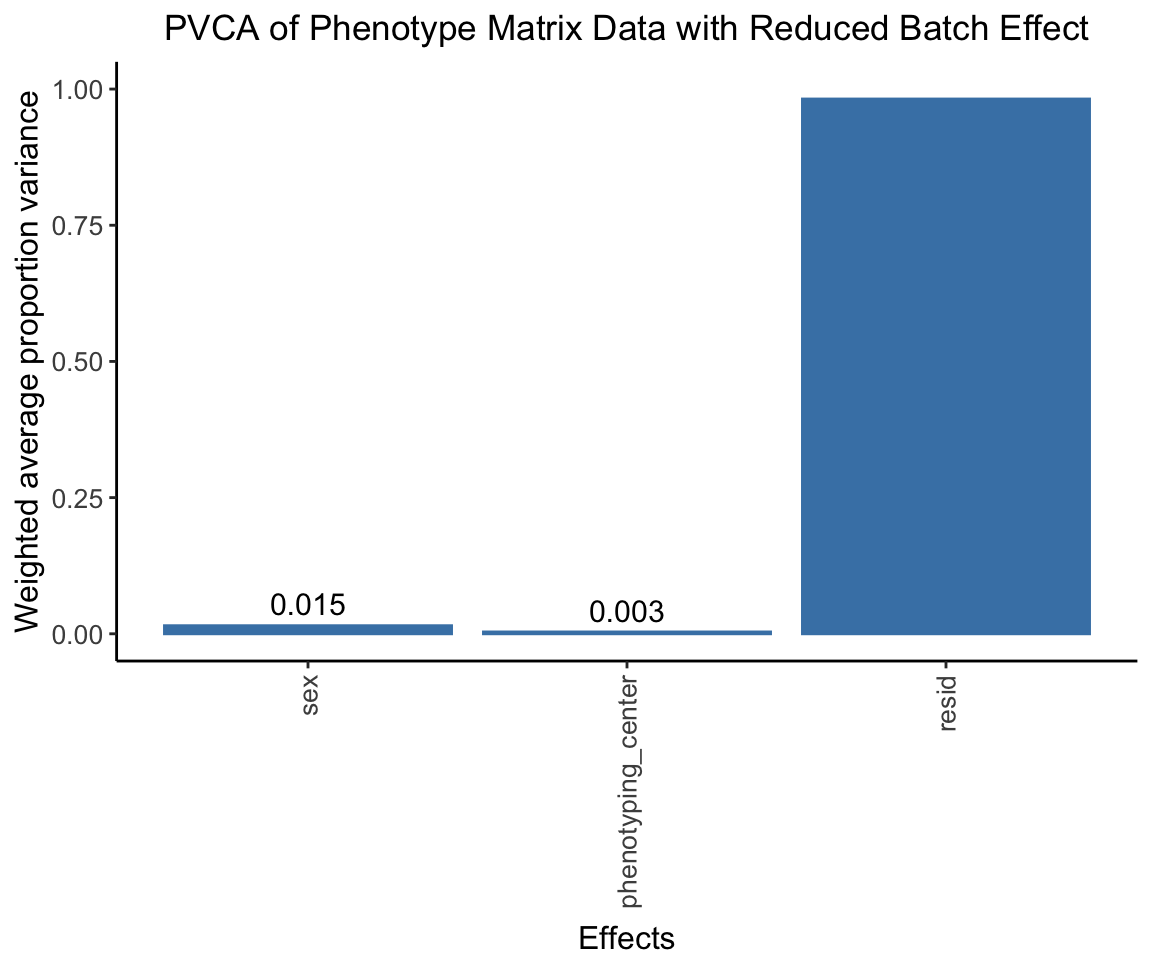
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
if(FALSE){
png(file="docs/figure/figures.Rmd/pvca_OF_2_v16.png", width=600, height=350)
pvca.plot.nobatch
dev.off()
}Computing phenotypic correlations
We compute the phenotype correlations using different methods and compare them.
OF.cor.rank <- cor(OF.mat.rank[,-1:-3], use="pairwise.complete.obs") # pearson correlation coefficient
OF.cor <- cor(OF.mat[,-1:-3], use="pairwise.complete.obs", method="spearman") # spearman
OF.cor.combat <- cor(t(combat_komp), use="pairwise.complete.obs")
pheno.list <- rownames(OF.cor)
ht1 = Heatmap(OF.cor, show_column_names = F, row_names_gp = gpar(fontsize = 9), name="Spearm. Corr.")
draw(ht1)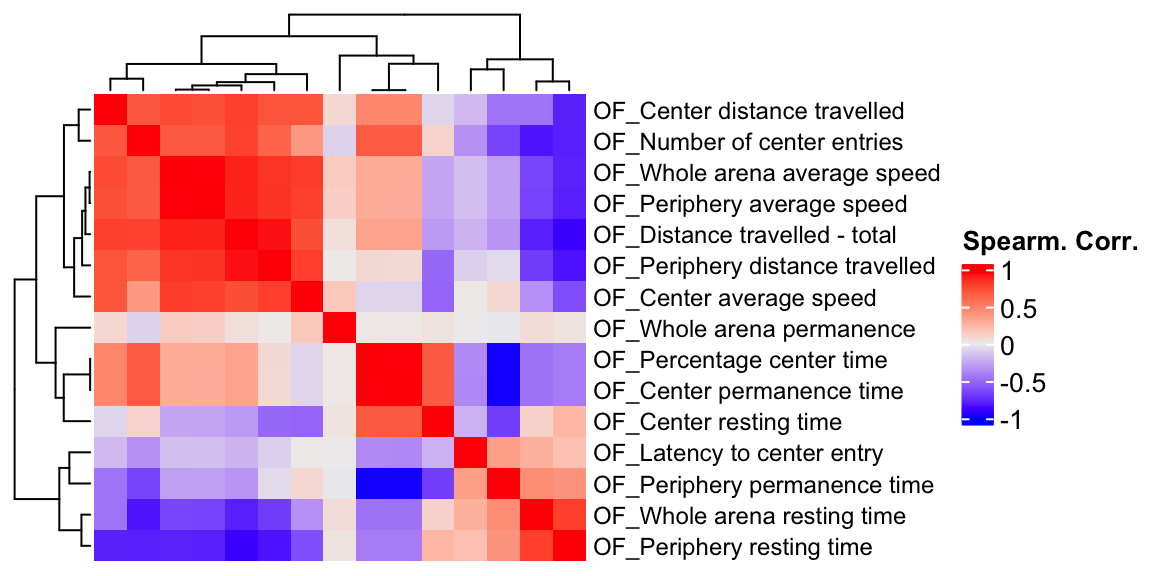
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
ht2 = Heatmap(OF.cor.rank, show_column_names = F, row_names_gp = gpar(fontsize = 9), name="Corr. RankZ")
draw(ht2)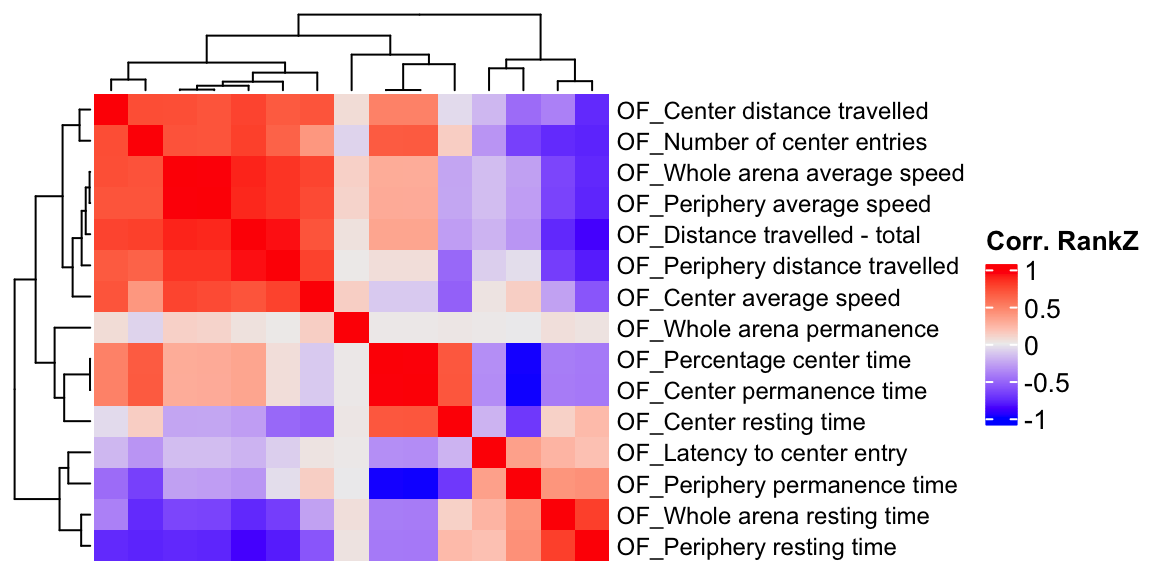
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
ht3 = Heatmap(OF.cor.combat, show_column_names = F, row_names_gp = gpar(fontsize = 9), name="Corr. ComBat")
draw(ht3)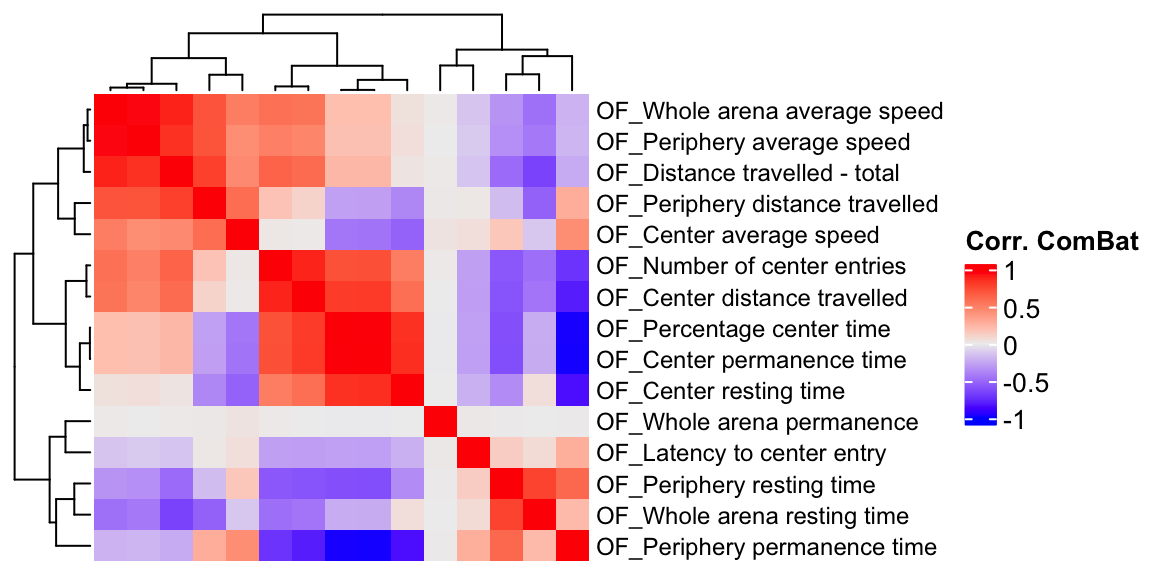
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
Preparation of IMPC summary statistics data
Loading Open Field summary stat (IMPCv16)
OF.stat <- readRDS("data/OF.stat.v16.rds")
dim(OF.stat)[1] 61854 8table(OF.stat$parameter_name, OF.stat$procedure_name)
OF
Center average speed 3896
Center distance travelled 4176
Center permanence time 4275
Center resting time 3570
Distance travelled - total 4201
Latency to center entry 2989
Number of center entries 3614
Number of rears - total 2553
Percentage center movement time 3600
Percentage center time 4275
Periphery average speed 4176
Periphery distance travelled 4176
Periphery permanence time 4275
Periphery resting time 3529
Whole arena average speed 4275
Whole arena resting time 4274#length(unique(OF.stat$marker_symbol)) #3362
#length(unique(OF.stat$allele_symbol)) #3412
#length(unique(OF.stat$proc_param_name)) #15, number of phenotypes in association statistics data set
#length(unique(OF.data$proc_param_name)) #15, number of phenotypes in final control data
pheno.list.stat <- unique(OF.stat$proc_param_name)
pheno.list.ctrl <- unique(OF.data$proc_param_name)
#sum(pheno.list.stat %in% pheno.list.ctrl)
#sum(pheno.list.ctrl %in% pheno.list.stat)
# Identifying common phenotypes between statistics and control data
common.pheno.list <- sort(intersect(pheno.list.ctrl, pheno.list.stat))
common.pheno.list [1] "OF_Center average speed" "OF_Center distance travelled"
[3] "OF_Center permanence time" "OF_Center resting time"
[5] "OF_Distance travelled - total" "OF_Latency to center entry"
[7] "OF_Number of center entries" "OF_Percentage center time"
[9] "OF_Periphery average speed" "OF_Periphery distance travelled"
[11] "OF_Periphery permanence time" "OF_Periphery resting time"
[13] "OF_Whole arena average speed" "OF_Whole arena resting time" #length(common.pheno.list) # 14 - each data set had one phenotype not present in the other
# Filtering summary statistics to contain only common phenotypes
#dim(OF.stat)
OF.stat <- OF.stat %>% filter(proc_param_name %in% common.pheno.list)
#dim(OF.stat)
#length(unique(OF.stat$proc_param_name))Visualizing gene-phenotype pair duplicates
mtest <- table(OF.stat$proc_param_name, OF.stat$marker_symbol)
mtest <-as.data.frame.matrix(mtest)
nmax <-max(mtest)
col_fun = colorRamp2(c(0, nmax), c("white", "red"))
#col_fun(seq(0, nmax))
ht = Heatmap(as.matrix(mtest), cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, col = col_fun,
row_names_gp = gpar(fontsize = 8), name="Count")
draw(ht)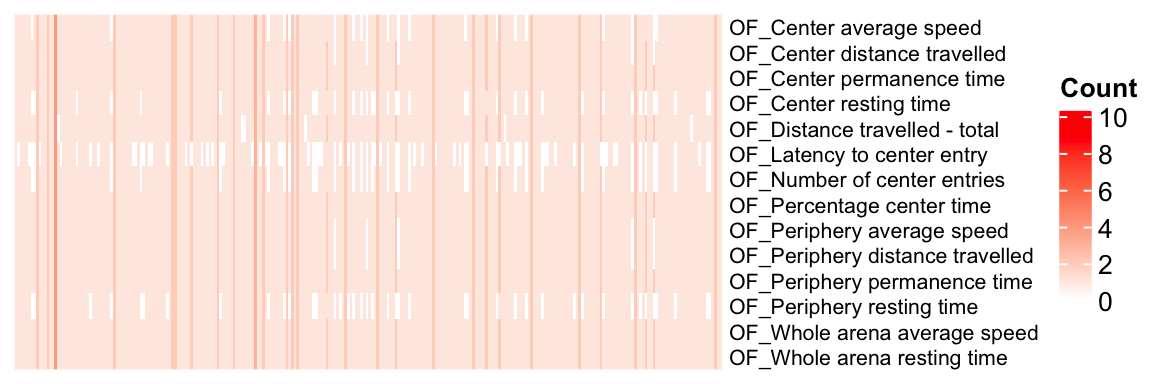
| Version | Author | Date |
|---|---|---|
| 7685a09 | statsleelab | 2023-01-10 |
Consolidating muliple z-scores of a gene-phenotype pair using Stouffer’s Method
## sum(z-score)/sqrt(# of zscore)
sumz <- function(z){ sum(z)/sqrt(length(z)) }
OF.z = OF.stat %>%
dplyr::select(marker_symbol, proc_param_name, z_score) %>%
na.omit() %>%
group_by(marker_symbol, proc_param_name) %>%
summarize(zscore = sumz(z_score)) ## combine z-scores
#dim(OF.z)Generating Z-score matrix (reformatting)
# Function to convert NaN to NA
nan2na <- function(df){
out <- data.frame(sapply(df, function(x) ifelse(is.nan(x), NA, x)))
colnames(out) <- colnames(df)
out
}
# Converting the long format of z-scores to a wide format matrix
OF.zmat = dcast(OF.z, marker_symbol ~ proc_param_name, value.var = "zscore",
fun.aggregate = mean) %>% tibble::column_to_rownames(var="marker_symbol")
OF.zmat = nan2na(OF.zmat) #convert nan to na
#dim(OF.zmat)Visualization of Phenotype-Gene Coverage
The heatmap illustrates tested (red) and untested (white) gene-phenotype pairs.
# Generate a matrix indicating where z-scores are present
id.mat <- 1*(!is.na(OF.zmat)) # multiply 1 to make this matrix numeric
#nrow(as.data.frame(colSums(id.mat)))
#dim(id.mat)
ht = Heatmap(t(id.mat),
cluster_rows = T, clustering_distance_rows ="binary",
cluster_columns = T, clustering_distance_columns = "binary",
show_row_dend = F, show_column_dend = F, # do not show dendrogram
show_column_names = F, col = c("white","red"),
row_names_gp = gpar(fontsize = 10), name="Missing")
draw(ht)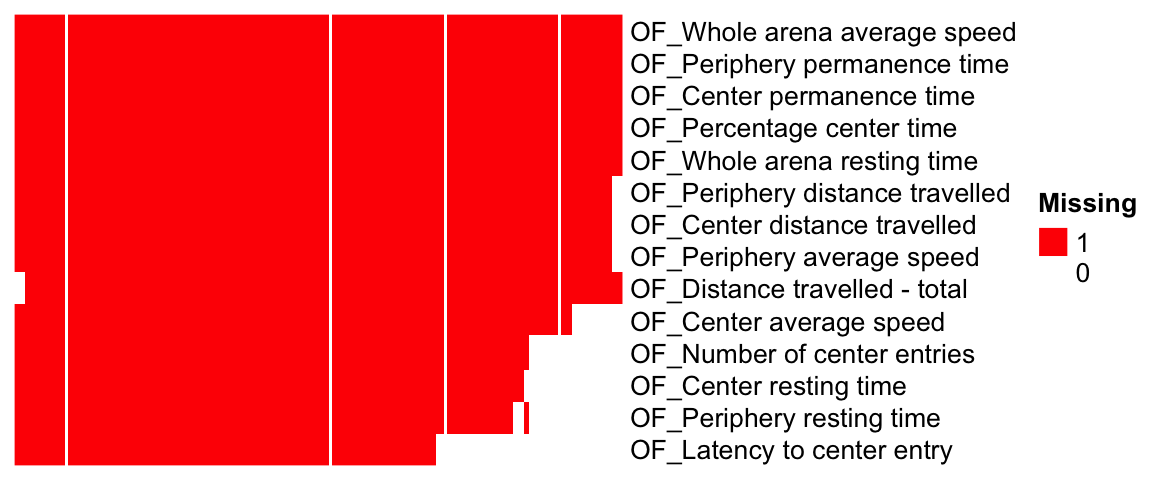
Distribution of Z-Scores Across Phenotypes
The histogram presents the distribution of association Z-scores for each phenotype.
ggplot(melt(OF.zmat), aes(x=value)) +
geom_histogram() +
facet_wrap(~variable, scales="free", ncol=5)+
theme(strip.text.x = element_text(size = 6))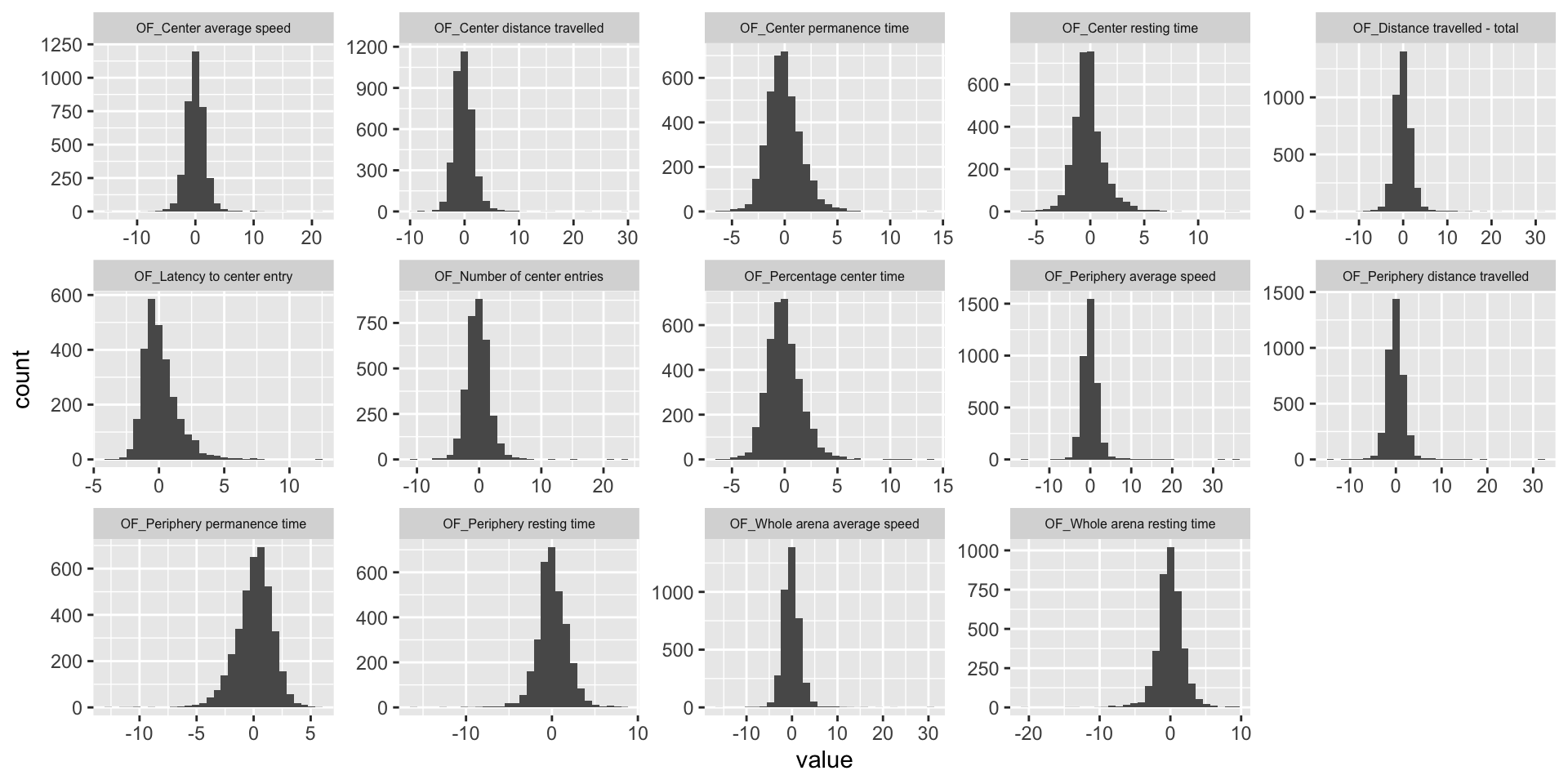
Estimation of Genetic Correlation Matrix Using Z-Scores
Here, we estimate the genetic correlations between phenotypes utilizing the association Z-score matrix.
# Select common phenotypes
OF.zmat <- OF.zmat[,common.pheno.list]
#dim(OF.zmat)
# Compute genetic correlations
OF.zcor = cor(OF.zmat, use="pairwise.complete.obs")
# Generate heatmap of the correlation matrix
ht = Heatmap(OF.zcor, cluster_rows = T, cluster_columns = T, show_column_names = F, #col = col_fun,
row_names_gp = gpar(fontsize = 10),
name="Genetic Corr (Z-score)"
)
draw(ht)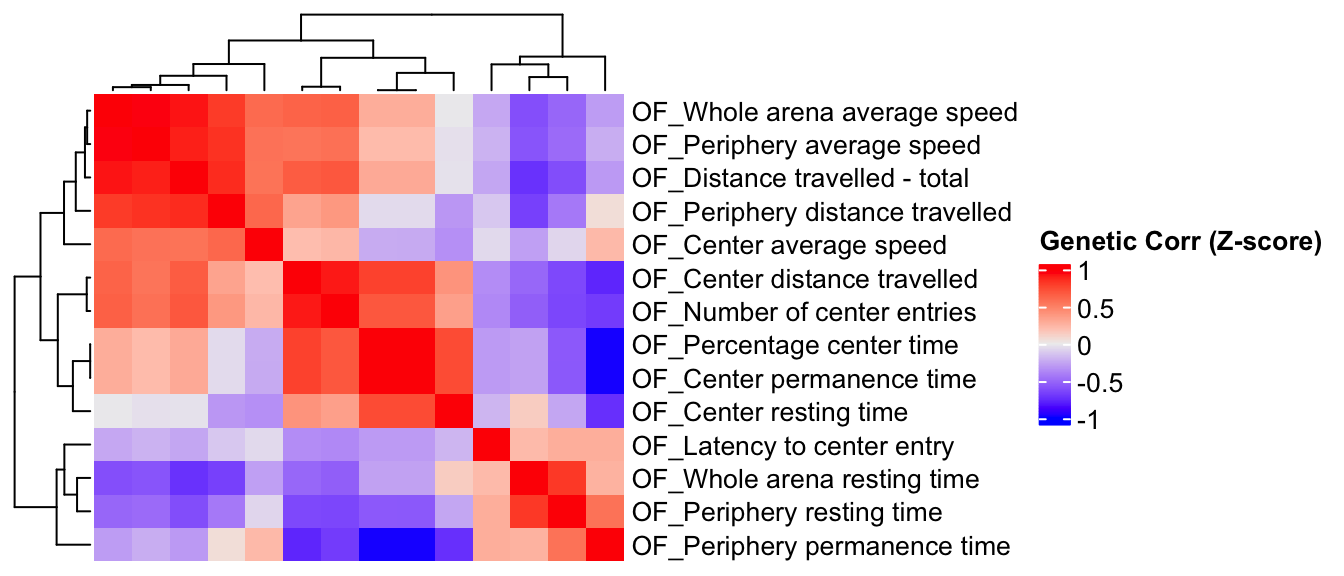
Comparison of Phenotypic Correlation and Genetic Correlation Among Phenotypes
We will compare the correlation matrix obtained from control mice phenotype data and the genetic correlation matrix estimated using association Z-scores. As depicted below, both correlation heatmaps show similar correlation patterns.
OF.cor.rank.fig <- OF.cor.rank[common.pheno.list,common.pheno.list]
OF.cor.fig <- OF.cor[common.pheno.list,common.pheno.list]
OF.cor.combat.fig <- OF.cor.combat[common.pheno.list, common.pheno.list]
OF.zcor.fig <- OF.zcor
ht = Heatmap(OF.cor.rank.fig, cluster_rows = TRUE, cluster_columns = TRUE, show_column_names = F, #col = col_fun,
show_row_dend = F, show_column_dend = F, # do not show dendrogram
row_names_gp = gpar(fontsize = 8), column_title="Phenotype Corr (RankZ, Pearson)", column_title_gp = gpar(fontsize = 8),
name="Corr")
pheno.order <- row_order(ht)
#draw(ht)
OF.cor.rank.fig <- OF.cor.rank.fig[pheno.order,pheno.order]
ht1 = Heatmap(OF.cor.rank.fig, cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, #col = col_fun,
show_row_dend = F, show_column_dend = F, # do not show dendrogram
row_names_gp = gpar(fontsize = 8), column_title="Phenotype Corr (RankZ, Pearson)", column_title_gp = gpar(fontsize = 8),
name="Corr")
OF.cor.fig <- OF.cor.fig[pheno.order,pheno.order]
ht2 = Heatmap(OF.cor.fig, cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, #col = col_fun,
row_names_gp = gpar(fontsize = 8), column_title="Phenotype Corr (Spearman)", column_title_gp = gpar(fontsize = 8),
name="Corr")
OF.cor.combat.fig <- OF.cor.combat.fig[pheno.order,pheno.order]
ht3 = Heatmap(OF.cor.combat.fig, cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, #col = col_fun,
row_names_gp = gpar(fontsize = 8), column_title="Phenotype Corr (Combat, Pearson)", column_title_gp = gpar(fontsize = 8),
name="Corr")
OF.zcor.fig <- OF.zcor.fig[pheno.order,pheno.order]
ht4 = Heatmap(OF.zcor.fig, cluster_rows = FALSE, cluster_columns = FALSE, show_column_names = F, #col = col_fun,
row_names_gp = gpar(fontsize = 8), column_title="Genetic Corr (Pearson)", column_title_gp = gpar(fontsize = 8),
name="Corr"
)
draw(ht1+ht2+ht3+ht4)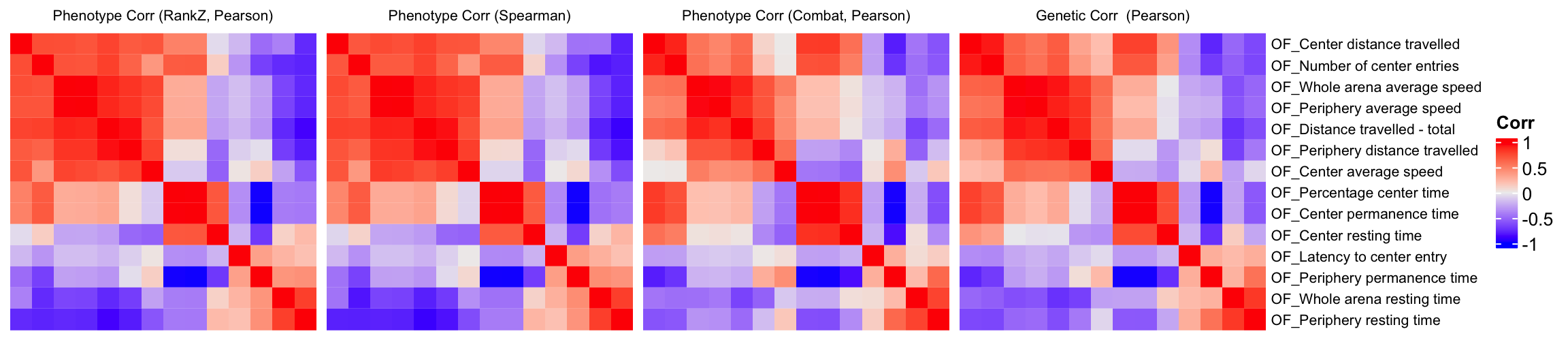
if(FALSE){
png(file="docs/figure/figures.Rmd/cors_OF.png", width=800, height=250)
draw(ht1+ht2+ht3+ht4)
dev.off()
}Correlation Analysis Between Genetic Correlation Matrices Using Mantel’s Test
To evaluate the correlation between different genetic correlation matrices, we apply Mantel’s test, which measures the correlation between two distance matrices.
####################
# Use Mantel test
# https://stats.idre.ucla.edu/r/faq/how-can-i-perform-a-mantel-test-in-r/
# install.packages("ade4")
library(ade4)
# Function to extract upper triangular elements of a matrix
to.upper<-function(X) X[upper.tri(X,diag=FALSE)]
a1 <- to.upper(OF.cor.fig)
a2 <- to.upper(OF.cor.rank.fig)
a3 <- to.upper(OF.cor.combat.fig)
a4 <- to.upper(OF.zcor.fig)
plot(a4, a1)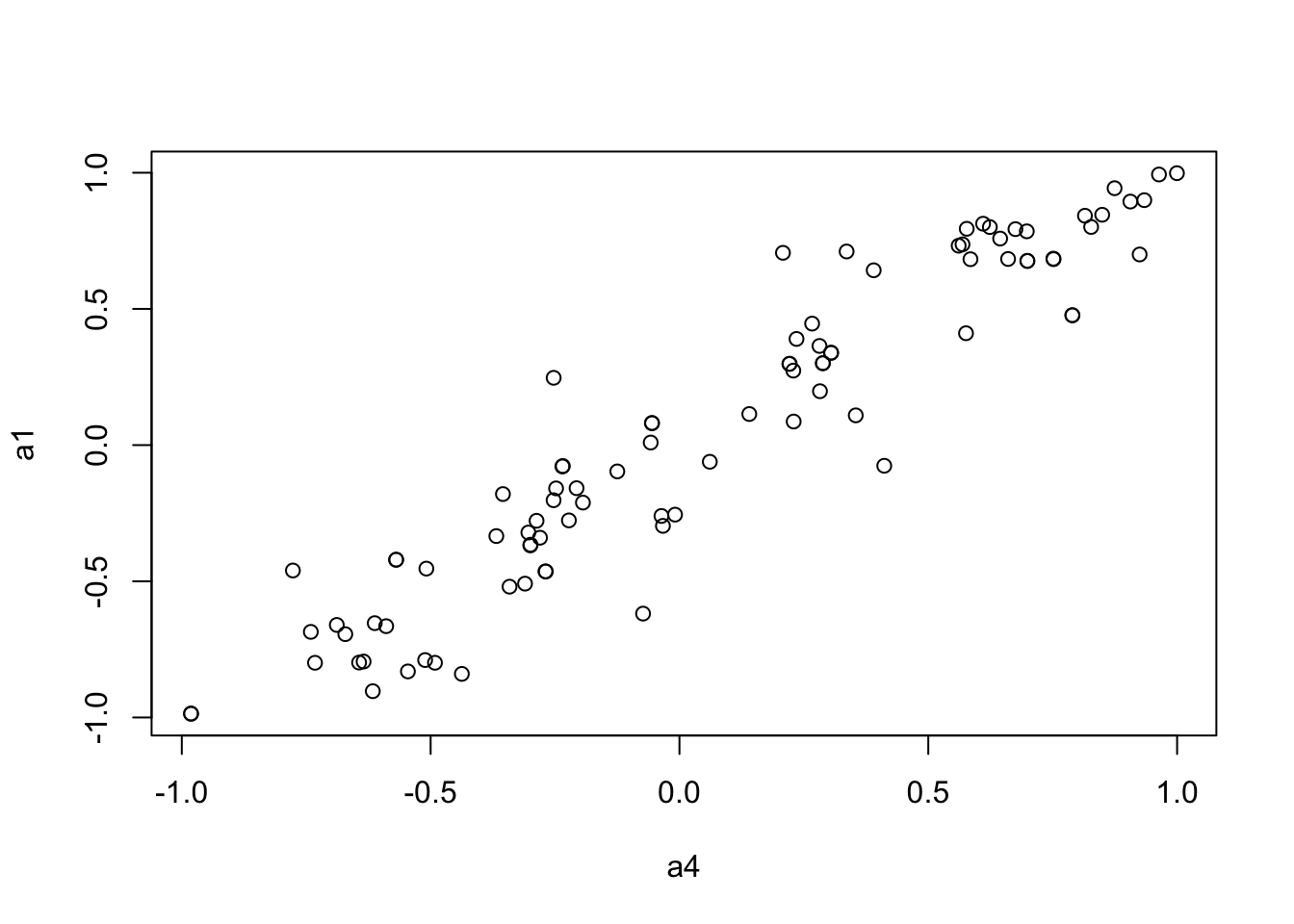
| Version | Author | Date |
|---|---|---|
| 9b680ec | statsleelab | 2023-06-20 |
plot(a4, a2)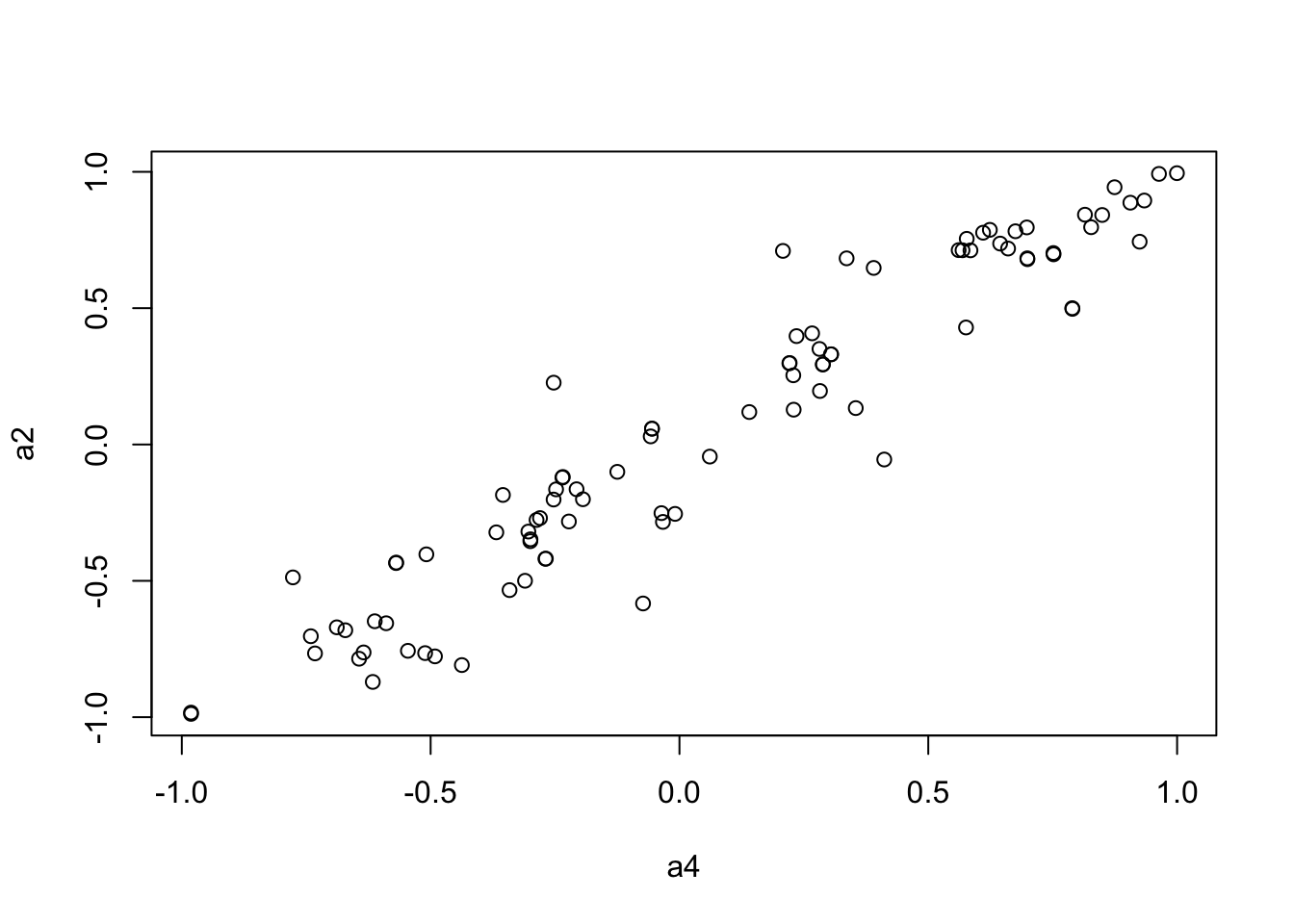
| Version | Author | Date |
|---|---|---|
| 9b680ec | statsleelab | 2023-06-20 |
plot(a4, a3)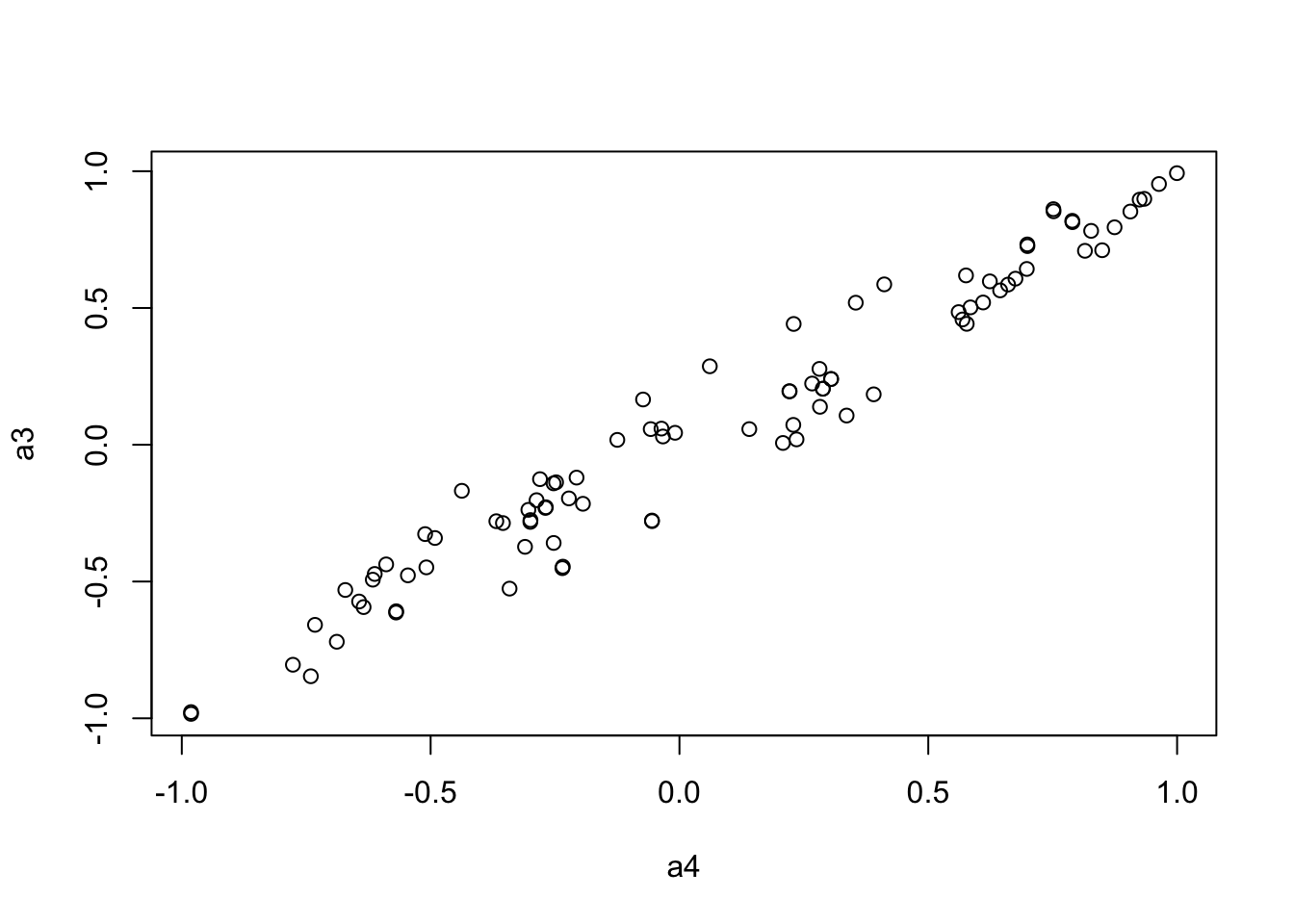
| Version | Author | Date |
|---|---|---|
| 9b680ec | statsleelab | 2023-06-20 |
mantel.rtest(as.dist(1-OF.cor.fig), as.dist(1-OF.zcor.fig), nrepet = 9999) #nrepet = number of permutationsMonte-Carlo test
Call: mantelnoneuclid(m1 = m1, m2 = m2, nrepet = nrepet)
Observation: 0.9481883
Based on 9999 replicates
Simulated p-value: 1e-04
Alternative hypothesis: greater
Std.Obs Expectation Variance
8.2821799635 -0.0003203414 0.0131157538 mantel.rtest(as.dist(1-OF.cor.rank.fig), as.dist(1-OF.zcor.fig), nrepet = 9999)Monte-Carlo test
Call: mantelnoneuclid(m1 = m1, m2 = m2, nrepet = nrepet)
Observation: 0.9544471
Based on 9999 replicates
Simulated p-value: 1e-04
Alternative hypothesis: greater
Std.Obs Expectation Variance
8.2504397969 0.0008944113 0.0133578074 mantel.rtest(as.dist(1-OF.cor.combat.fig), as.dist(1-OF.zcor.fig), nrepet = 9999)Monte-Carlo test
Call: mantelnoneuclid(m1 = m1, m2 = m2, nrepet = nrepet)
Observation: 0.9759421
Based on 9999 replicates
Simulated p-value: 1e-04
Alternative hypothesis: greater
Std.Obs Expectation Variance
8.920438043 -0.001681222 0.012010766 Evaluating the KOMPUTE Imputation Algorithm
Initializing the KOMPUTE Package
# Check if KOMPUTE is installed, if not, install it from GitHub using devtools
if(!"kompute" %in% rownames(installed.packages())){
library(devtools)
devtools::install_github("dleelab/kompute")
}
library(kompute)Simulation study - Comparison of imputed vs measured z-score values
In this section, we conduct a simulation study to compare the performance of the KOMPUTE method with the measured gene-phenotype association z-scores. We randomly select some of these measured z-scores, mask them, and then use the KOMPUTE method to impute them. We then compare the imputed z-scores with the measured ones.
zmat <-t(OF.zmat)
dim(zmat)[1] 14 3823# filter genes with less than 1 missing data point (na)
zmat0 <- is.na(zmat)
num.na<-colSums(zmat0)
#summary(num.na)
#dim(zmat)
#dim(zmat[,num.na<1])
#dim(zmat[,num.na<5])
#dim(zmat[,num.na<10])
# filter genes with less than 1 missing data point (na)
zmat <- zmat[,num.na<1]
#dim(zmat)
# Set correlation method for phenotypes
#pheno.cor <- OF.cor.fig
#pheno.cor <- OF.cor.rank.fig
pheno.cor <- OF.cor.combat.fig
#pheno.cor <- OF.zcor.fig
zmat <- zmat[rownames(pheno.cor),,drop=FALSE]
#rownames(zmat)
#rownames(pheno.cor)
#colnames(pheno.cor)
npheno <- nrow(zmat)
# calculate the percentage of missing Z-scores in the original data
100*sum(is.na(zmat))/(nrow(zmat)*ncol(zmat)) # 0%[1] 0nimp <- 1000 # # of missing/imputed Z-scores
set.seed(1111)
# find index of all measured zscores
all.i <- 1:(nrow(zmat)*ncol(zmat))
measured <- as.vector(!is.na(as.matrix(zmat)))
measured.i <- all.i[measured]
# mask 2000 measured z-scores
mask.i <- sort(sample(measured.i, nimp))
org.z = as.matrix(zmat)[mask.i]
zvec <- as.vector(as.matrix(zmat))
zvec[mask.i] <- NA
zmat.imp <- matrix(zvec, nrow=npheno)
rownames(zmat.imp) <- rownames(zmat)Run KOMPUTE method
kompute.res <- kompute(t(zmat.imp), pheno.cor, 0.01)
# Compare measured vs imputed z-scores
#length(org.z)
imp.z <- as.matrix(t(kompute.res$zmat))[mask.i]
imp.info <- as.matrix(t(kompute.res$infomat))[mask.i]
# Create a dataframe with the original and imputed z-scores and the information of imputed z-scores
imp <- data.frame(org.z=org.z, imp.z=imp.z, info=imp.info)
#dim(imp)
imp <- imp[complete.cases(imp),]
imp <- subset(imp, info>=0 & info <= 1)
#dim(imp)
cor.val <- round(cor(imp$imp.z, imp$org.z), digits=3)
#cor.val
g <- ggplot(imp, aes(x=imp.z, y=org.z)) +
geom_point() +
labs(title=paste0("IMPC OF Data, Cor=",cor.val),
x="Imputed Z-scores", y = "Measured Z-scores") +
theme_minimal()
g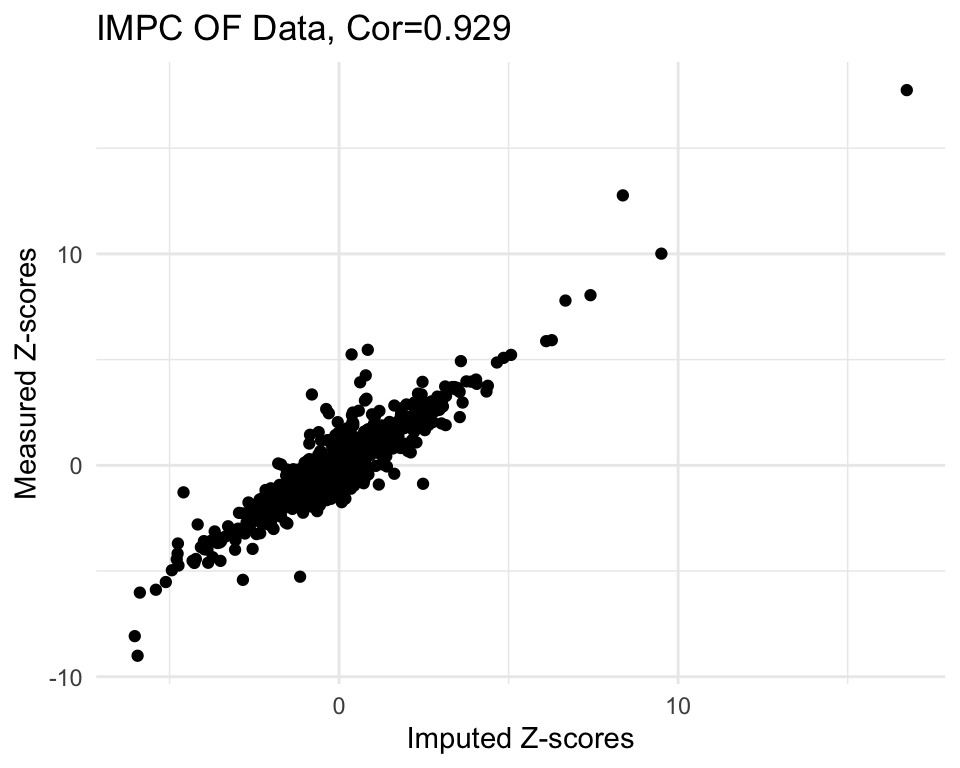
# Set a cutoff for information content and filter the data accordingly
info.cutoff <- 0.8
imp.sub <- subset(imp, info>info.cutoff)
#dim(imp.sub)
#summary(imp.sub$imp.z)
#summary(imp.sub$info)
cor.val <- round(cor(imp.sub$imp.z, imp.sub$org.z), digits=3)
#cor.val
g <- ggplot(imp.sub, aes(x=imp.z, y=org.z, col=info)) +
geom_point() +
labs(title=paste0("IMPC Behavior Data (OF), Info>", info.cutoff, ", Cor=",cor.val),
x="Imputed Z-scores", y = "Measured Z-scores", col="Info") +
theme_minimal()
g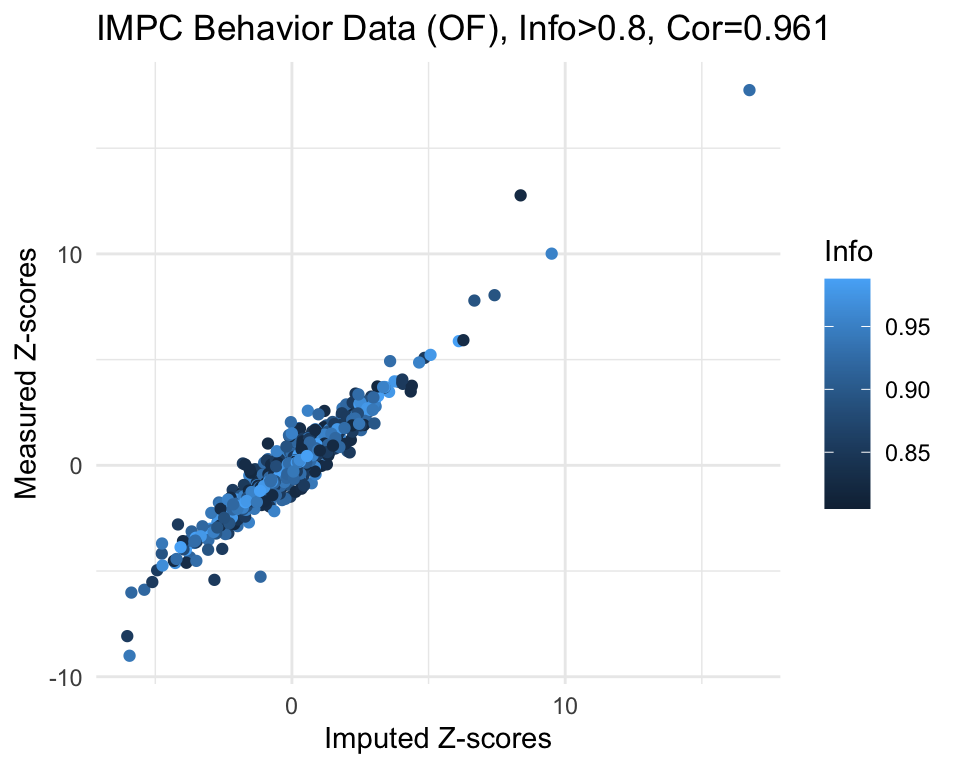
# save plot
png(file="docs/figure/figures.Rmd/sim_results_OF_v16.png", width=600, height=350)
g
dev.off()quartz_off_screen
2 # Part 3 of Figure 2
fig2.3 <- ggplot(imp.sub, aes(x=imp.z, y=org.z, col=info)) +
geom_point() +
labs(title="Open Field",
x="Imputed Z-scores", y = "", col="Info") +
scale_x_continuous(limits=c(-9,9), breaks=c(seq(-9,9,3)), minor_breaks = NULL) +
scale_y_continuous(limits=c(-9,9), breaks=c(seq(-9,9,3))) +
scale_color_gradient(limits=c(0.8,1), low="#98cdf9", high="#084b82") +
theme_bw() +
#theme(legend.position="none", plot.title=element_text(hjust=0.5))
theme(plot.title=element_text(hjust=0.5))
save(fig2.3, file="docs/figure/figures.Rmd/sim_OF_v16.rdata")Run SVD Matrix Completion method
# load SVD Matrix Completion function
source("code/svd_impute.R")
r <- 6
mc.res <- svd.impute(zmat.imp, r)
# Compare measured vs imputed z-scores
length(org.z)[1] 1000imp.z <- mc.res[mask.i]
#plot(imp.z, org.z)
#cor(imp.z, org.z)
# Create a dataframe with the original and imputed z-scores and the information of imputed z-scores
imp2 <- data.frame(org.z=org.z, imp.z=imp.z)
#dim(imp2)
imp2 <- imp2[complete.cases(imp2),]
cor.val <- round(cor(imp2$imp.z, imp2$org.z), digits=3)
#cor.val
g <- ggplot(imp2, aes(x=imp.z, y=org.z)) +
geom_point() +
labs(title=paste0("IMPC OF Data, Cor=",cor.val),
x="Imputed Z-scores", y = "Measured Z-scores") +
theme_minimal()
g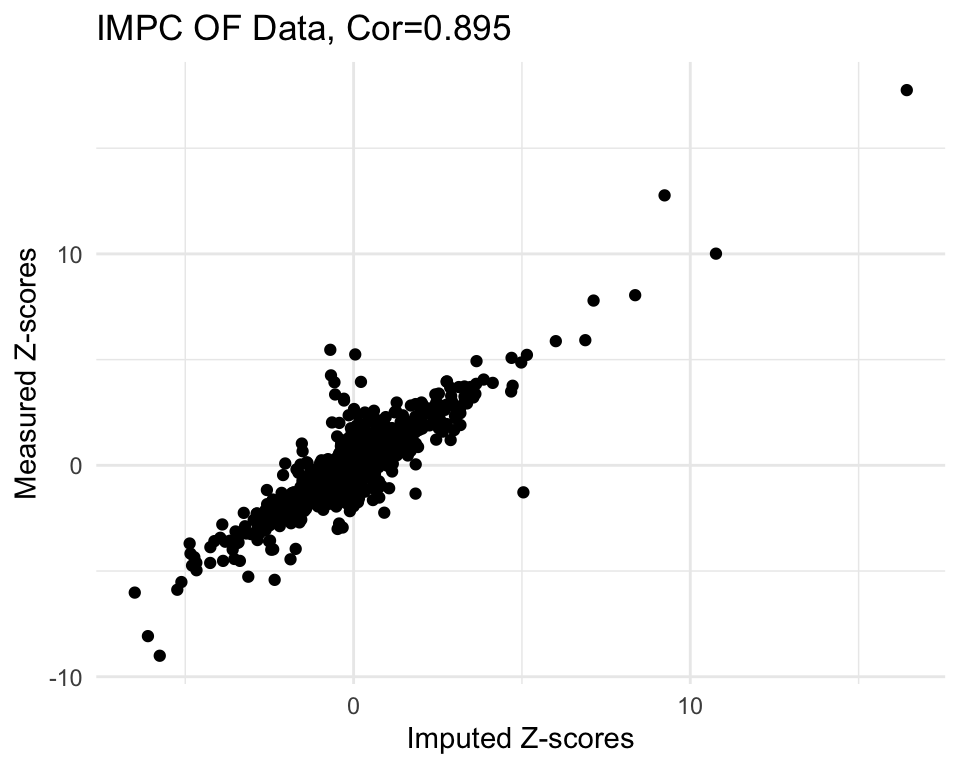
| Version | Author | Date |
|---|---|---|
| b343ff3 | statsleelab | 2023-07-03 |
Save imputation results
imp$method <- "KOMPUTE"
imp2$method <- "SVD-MC"
imp2$info <- NA
OF_Imputation_Result <- rbind(imp, imp2)
save(OF_Imputation_Result, file = "data/OF.imp.res.v16.RData")Save z-score matrix and phenotype correlation matrix
plist <- sort(colnames(OF.zmat))
OF_Zscore_Mat <- as.matrix(OF.zmat[,plist])
save(OF_Zscore_Mat, file = "data/OF.zmat.v16.RData")
OF_Pheno_Cor <- pheno.cor[plist,plist]
save(OF_Pheno_Cor, file = "data/OF.pheno.cor.v16.RData")
sessionInfo()R version 4.2.1 (2022-06-23)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] kompute_0.1.0 ade4_1.7-20 sva_3.44.0
[4] BiocParallel_1.30.3 genefilter_1.78.0 mgcv_1.8-40
[7] nlme_3.1-158 lme4_1.1-31 Matrix_1.5-1
[10] RNOmni_1.0.1 ComplexHeatmap_2.12.1 circlize_0.4.15
[13] RColorBrewer_1.1-3 tidyr_1.2.0 ggplot2_3.4.1
[16] reshape2_1.4.4 dplyr_1.0.9 data.table_1.14.2
[19] workflowr_1.7.0.1
loaded via a namespace (and not attached):
[1] minqa_1.2.5 colorspace_2.1-0 rjson_0.2.21
[4] rprojroot_2.0.3 XVector_0.36.0 GlobalOptions_0.1.2
[7] fs_1.5.2 clue_0.3-62 rstudioapi_0.13
[10] farver_2.1.1 bit64_4.0.5 AnnotationDbi_1.58.0
[13] fansi_1.0.4 codetools_0.2-18 splines_4.2.1
[16] doParallel_1.0.17 cachem_1.0.6 knitr_1.39
[19] jsonlite_1.8.0 nloptr_2.0.3 annotate_1.74.0
[22] cluster_2.1.3 png_0.1-8 compiler_4.2.1
[25] httr_1.4.3 assertthat_0.2.1 fastmap_1.1.0
[28] limma_3.52.4 cli_3.6.0 later_1.3.0
[31] htmltools_0.5.3 tools_4.2.1 gtable_0.3.1
[34] glue_1.6.2 GenomeInfoDbData_1.2.8 Rcpp_1.0.10
[37] Biobase_2.56.0 jquerylib_0.1.4 vctrs_0.5.2
[40] Biostrings_2.64.0 iterators_1.0.14 xfun_0.31
[43] stringr_1.4.0 ps_1.7.1 lifecycle_1.0.3
[46] XML_3.99-0.10 edgeR_3.38.4 getPass_0.2-2
[49] MASS_7.3-58.1 zlibbioc_1.42.0 scales_1.2.1
[52] promises_1.2.0.1 parallel_4.2.1 yaml_2.3.5
[55] memoise_2.0.1 sass_0.4.2 stringi_1.7.8
[58] RSQLite_2.2.15 highr_0.9 S4Vectors_0.34.0
[61] foreach_1.5.2 BiocGenerics_0.42.0 boot_1.3-28
[64] shape_1.4.6 GenomeInfoDb_1.32.3 rlang_1.0.6
[67] pkgconfig_2.0.3 matrixStats_0.62.0 bitops_1.0-7
[70] evaluate_0.16 lattice_0.20-45 purrr_0.3.4
[73] labeling_0.4.2 bit_4.0.4 processx_3.7.0
[76] tidyselect_1.2.0 plyr_1.8.7 magrittr_2.0.3
[79] R6_2.5.1 IRanges_2.30.0 generics_0.1.3
[82] DBI_1.1.3 pillar_1.8.1 whisker_0.4
[85] withr_2.5.0 survival_3.3-1 KEGGREST_1.36.3
[88] RCurl_1.98-1.8 tibble_3.1.8 crayon_1.5.1
[91] utf8_1.2.3 rmarkdown_2.14 GetoptLong_1.0.5
[94] locfit_1.5-9.6 blob_1.2.3 callr_3.7.1
[97] git2r_0.30.1 digest_0.6.29 xtable_1.8-4
[100] httpuv_1.6.5 stats4_4.2.1 munsell_0.5.0
[103] bslib_0.4.0